728x90
분할 정복 알고리즘
엄청나게 크고 방대한 문제를 조금씩 조금씩 나눠가면서 용이하게 풀 수 있는 문제 단위로 나눈 다음
그것들을 다시 합쳐서 해결하는 개념
- 대표적으로 퀵소트, 병합정렬이 있음
- 문제를 둘 이상의 부분 분제로 나누는 자연스러운 방법이 있어야 함
- 부분 문제의 답을 조합해 원래 문제의 답을 계산하는 효율적인 방법이 있어야 함
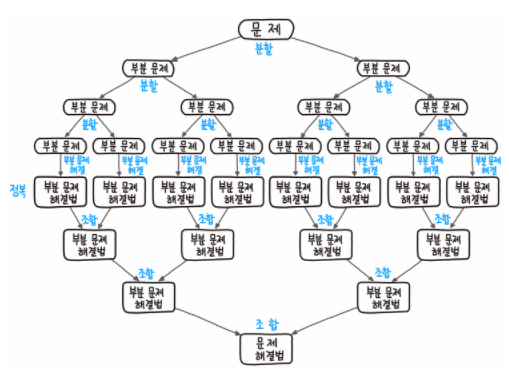
분할: 문제를 동일한 유형의 여러 하위 문제로 나눔
정복: 가장 작은 단위의 하위 문제를 해결하여 정복
조합: 하위 문제에 대한 결과를 원래 문제에 대한 결과로 조합
장점
- 문제를 나누어 해결한다는 특징상 병렬적으로 문제를 해결하는 데 큰 강점을 가짐
- 같은 작업을 더 빠르게 처리가 가능
단점
- 함수를 재귀적으로 호출한다는 점에서 함수 호출로 인한 오버헤드가 발생
- 스택에 다양한 데이터를 보관하고 있어야 하므로 스택 오버플로우가 발생, 과도한 메모리 사용을 하게 됨
'자료구조' 카테고리의 다른 글
| 브루트 포스 알고리즘 (brute force), 백트래킹 (Backtracing) 알고리즘 (0) | 2021.05.12 |
|---|---|
| 벨만 포드 (Bellman-Ford) 알고리즘 (0) | 2021.05.12 |
| 그리디 알고리즘 (Greedy Algorithm) (0) | 2021.05.12 |
| 해싱 (Hashing), 해시 충돌 (Hash Collision), 체이닝 (Chaining), 개방 주소법 (Open Addressing) (0) | 2021.05.12 |
| B-트리, B+트리, 2-3 트리, 2-3-4 트리 (0) | 2021.05.12 |